
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 오준석의생존코딩
- 오존석의 생존코딩
- 오름캠프
- 플러터
- 패스트 캠퍼스
- 모두의 연구소 # 오준석의생존코딩# 오름캠프
- ㅇ
- 모두의연구소 오준석생존코딩 오름캠프
- 오준석의 생존코딩
- 오름캠프플러터
- Tag #패스트캠퍼스 #내일배움카드 #국비지원 #K디지털기초역량훈련 #바이트디그리 #자바인강
- #패스트캠퍼스 #내일배움카드 #국비지원 #K디지털기초역량훈련 #바이트디그리 #자바인강
- 모두의연구소
- 생존코딩
- 모두연구소
- Today
- Total
꾸준히 하고싶은 개발자
딥러닝 개념 본문
퍼셉트론 알고리즘
x1,x2는 입력신호
y는 출력신호 [임계값 θ 이하일때는 0, 넘어설 때는 1(활성상태-activate) 출력]
w1,w2는 가중치
(입력신호가 결과에 미치는 중요도를 결정하는 매개변수
퍼셉트론은 구조 변경 없이 매개변수(가중치와 임계값)만 변경함으로써 AND, OR, NAND 논리 회로를 만들 수 있다. – 선형분리 가능





경사하강 알고리즘
예측값(hypothesis)과 실제값(y_data)이 얼마나 차이가 나는지 수치화한것을 비용(cost)또는 손실(loss)이라고 함
비용함수는 예측값과 실제값의 차이를 제곱해서 평균 낸 값을 반환 이를 오차제곱평균(MSE-mean squared error)라고 함
비용 함수는 아래로 볼록한 2차방정식 그래프이므로 비용함수의 최소값을 구하려면 임의의(w,b)값을 선택한 후 비용이 적게 나오는 쪽으로 경사(gradient)를 타고 내려가면 된다. 이것이 경사 하강 알고리즘(gradient descent algorithm)
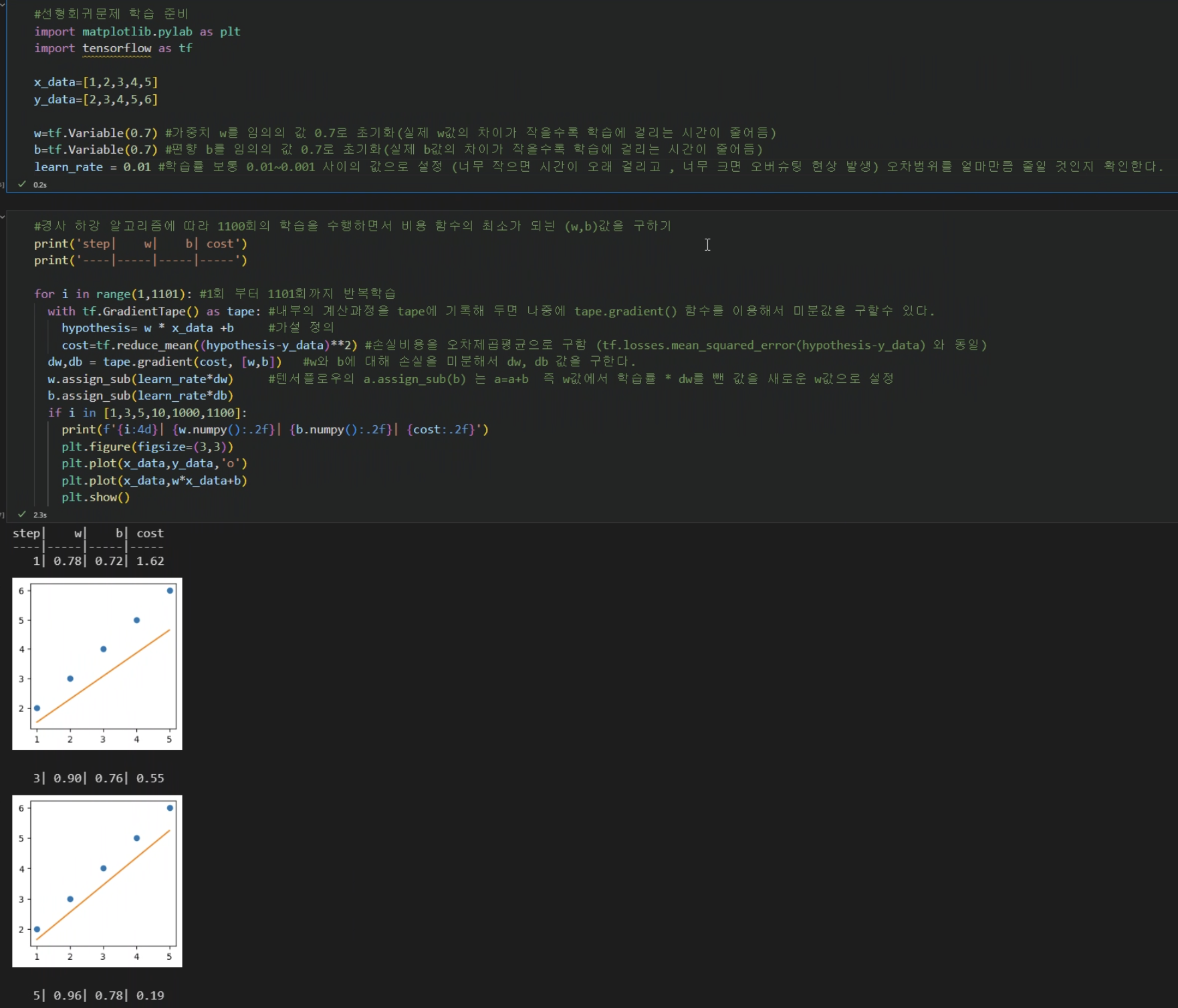


- 경사하강법은 오류가 작아지는 방향으로 가중치(w) 값을 보정하기위해 사용
- 경사하강법은 최최 가중치에서 부터 미분을 적용한뒤 미분값이 계속 감소하는 방법으로 순차적으로 가중치값을 업데이트한 후 업데이트가 끝나는 전역 최소점에서의 w를 반환한다.
활성화 함수(Activation Function)
입력 신호가 출력 결과에 미치는 영향도를조절하는 매개변수
활성화 함수를 사용하는 이유
출력값을 0~1 사이의 값으로 반환해야 하는 경우에 사용한다
비선형을 위해 사용한다
선형함수(y=w*x)일 경우 은닉층을 2개 사용한다면 식은 f(f(f(x))) = w*w*w*x = kx로 단순하게 변형됨. 은닉층 20개를 사용한다고 해도 동일한 결과가 나온다
즉, 선형함수로는 은닉층을 여러 개 추가해도 은닉층을 1개 추가한 것과 차이가 없기 때문에 정확한 결과를 위해선 비선형 함수(활성화 함수)가 필요하다
-활성화 함수: 입력 신호의 총합이 임계값을 넘어 설 때 특정값을 출력하는 함수

최근들어서는 ReLU 함수가 주로 사용한다.
∴(시그모이드 쓰면-미분값(최대값 0.25)이 작아서은닉층이 깊어질수록 학습이 안된다.)
계단 함수의 경우 0 or 1이 출력되지만 시그모이드 함수를 사용할 경우 0~1사이의 연속적인 실수가 출력된다. 퍼셉트론의 활성화 함수를 계단함수에서 시그모이드 함수로 변경해 비로서 복잡한 신경망에 대한 계산이 가능해짐(비선형)


소프트 맥스 함수는 분류 문제를 다룰 때 사용되는 활성화 함수로 입력받은 값들을 0~1 사이 값으로 정규화 한다. (출력값들의 총합은 항상1를 나온다.)
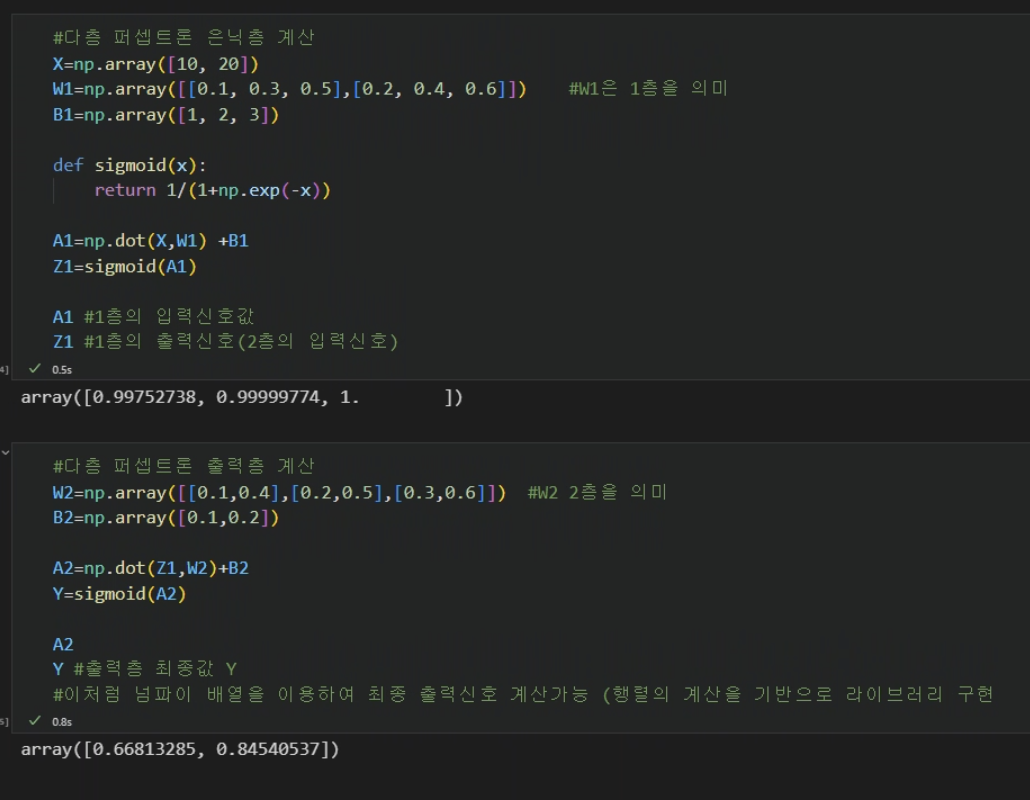
다충 퍼셉트론
a1: 퍼셉트론중 1번째 입력신호
z1: 퍼셉트론중 1번째 출력신호
b1 : 1번째 퍼셉트론으로 향하는 편향
w12: 1번째 퍼셉트론으로 향하는 그전 퍼셉트론(입력층) 가중치
h() : 활성함수
a1= x1w11 + x2w12 +b1
입력층으로 부터 세 개의 퍼셉트론 신호 전달되는 과정을 행렬의 내적을 이용하여 나타내면
A=XW + B
(a1 a2 a3) = (x1 x2) w11 w21 w31 + (b1 b2 b3)
w12 w22 w32

딥버닝
1990년대 심층 신경망은 과적합 문제와 느린 학습 시간으로 과학자들의 외면을 받는다. 대신 다차원 초평면을 학습하여 데이터를 분류하는 SVM이나 다수의 결정 트리를 학습하여 검출, 분류, 회귀 등을 수행하는 랜덤 포레스트 같은 머신러닝 기법들이 활발히 연구 된다.
2006년 제프리 힌트 교수가 신경망으로 데이터 차원 줄이기 논문을 발표하면서 심층 신경망도 과적합 없이 빠른 학습이 가능함이 알려지게 됨. 이 논문에서 손글씨 숫자데이터다.
(데이터마이닝)(MNIST)를 98.4% 수준으로 인식했으며 – 딥러닝용어 사용했다.
이후 일정한 확률에 따라 퍼셉트론을 무작위로 제거함으로써 과적합을 더욱 효과적으로 방지 할 수 있는 드롭아웃 개념이 나오고, 컴퓨터 파워 증가로 빅 데이터 대한 처리가 가능해지면서 딥러닝뿐 아니라 머신러닝 기술전반이 폭발적으로 발전한다.
tensorflow
Tensorflow: 구글에서 심층 신경망 연구를 위해 개발한 라이브러리로 2015년 11월에 오픈소스로 공개했다.
2019년 9월에 2.0릴리즈 : 대폭적인 변화와 더 높은 수준의 직관적인 케라스 Keras API를 사용할수 있게됨. 또한 즉시실행 모드가 기본설정 되어 있어 텐서프로 코드를 바로 실행가능(기존에는 세션객체를 생성후 run()메서드를 호출)
모든 데이터는 텐서(다차원 배열) 구조를 사용해서 표현. 텐서는 차원(rank), 형태(shape), 자료형(data typ)을 지니며 차원은 동적으로 변할 수 있다.

심층 순방향 신경망(DFN)
심층 순방향 신경망(Deep Feedforward Network, 이하 DFN)
딥러닝에서 가장 기본으로 사용하는 인공신경망(심층신경망이라고도 부름)
DFN은 입력층, 은닉층, 출력층으로 이루어져 있음.
이때 중요한 것은 은닉층이 2개 이상이어야 한다.
순방향이라 부르는 이유 : 데이터가 입력층→은닉층→출력층 순으로 전파된다.
순환 신경망(RNN)
순환 신경망(Recurrent Neural Network, 이하 RNN)
시계열 데이터와 같이 시간적으로 연속성이 있는 데이터를 처리하기 위해 고안된 인공신경망
시계열 데이터 : 일정한 시간 동안 관측되고 수집된 데이터다.
순환 신경망(RNN)
시계열 데이터가 딥러닝 신경망의 입력값으로 사용될 때, 데이터의 특성상 앞에 입력된 데이터가 뒤에 입력된 데이터에 영향을 주지않음
그래서 DFN으로는 시계열 데이터를 정확히 예측할 수 없다
RNN 구조와 DFN의 차이점
RNN은 은닉층의 각 뉴런에 순환 구조를 추가하여 이전에 입력된 데이터가 현재 데이터를 예측할 때 다시 사용될 수 있도록 함
따라서 현재 데이터를 분석할 때 과거 데이터를 고려한 정확한 데이터 예측한다.

LSTM
LSTM(Long Short-Term Memory)
RNN과는 다르게 신경망 내에 메모리를 두어 먼 과거의 데이터도 저장할 수 있도록 한다.
입출력을 제어하기 위한 소자를 두었는데, 이것을 게이트(Gate)라고 한다.
게이트는 입력 게이트, 출력 게이트, 망각 게이트가 있다

입력 게이트 : 현재의 정보를 기억하기 위한 소자임. 과거와 현재 데이터가 시그모이드 함수와 하이퍼볼릭 탄젠트 함수를 거치면서 현재 정보에 대한 보존량을 결정한다.
망각 게이트 : 과거의 정보를 어느 정도까지 기억할지 결정하는 소자이다.
출력 게이트 : 출력층으로 출력할 정보의 양을 결정하는 소자이다.

합성곱 신경망(CNN)
합성곱 신경망(Convolutional Neural Network, 이하 CNN)
인간의 시각 처리 방식을 모방한 신경망
이미지 처리가 가능하도록 합성곱(Convolution) 연산 도입했다.
CNN 종류

합성곱층(Convolutional Layer)
이미지를 분류하는 데 필요한 특징(Feature) 정보들을 추출하는 역할한다.
특징 정보는 필터를 이용해 추출한다.
합성곱층에 필터가 적용되면이미지의 특징들이 추출된 ‘특성 맵’이라는 결과를 얻을 수 있다.

풀링층(Pooling Layer)
합성곱층의 출력 데이터(특성 맵)를 입력으로 받아서 출력 데이터인 활성화 맵의 크기를 줄이거나 특정 데이터를 강조하는 용도로 사용
풀링층을 처리하는 방법 : 최대 풀링, 평균 풀링, 최소 풀링(Min Pooling)
완전연결층(Fully-connected Layer)
합성곱층과 풀링층으로 추출한 특징을 분류하는 역할
CNN은 합성곱층에서 특징만 학습하기 때문에 DFN이나 RNN에 비해 학습해야 하는 가중치의 수가 적어 학습 및 예측이 빠르다는 장점이 있음
최근에는 CNN의 강력한 예측 성능과 계산상의 효율성을 바탕으로 이미지뿐만 아니라 시계열 데이터에도 적용해 보는 연구가 활발히 진행되고 있다.
적대적 생성 신경망(Generative Adversarial Network, 이하 GAN)
2개의 신경망 모델이 서로 경쟁하면서 더 나은 결과를 만들어 내는 강화학습하며
특히 이미지 생성 분야에서 뛰어난 성능을 보이고 있다,
기존 인공신경망과는 다르게 두 개의 인공신경망이 서로 경쟁하며 학습 진행한다
이를 생성 모델(Generator Model)과 판별 모델 (Discriminator Model)이라고 하며, 각각은 서로 다른 목적을 가지고 학습한다.
생성 모델 : 주어진 데이터와 최대한 유사한 가짜 데이터를 생성한다.
판별 모델 : 진짜 데이터와 가짜 데이터 중 어떤 것이 진짜 데이터인지를 판별한다.