
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 패스트 캠퍼스
- Tag #패스트캠퍼스 #내일배움카드 #국비지원 #K디지털기초역량훈련 #바이트디그리 #자바인강
- ㅇ
- 오준석의생존코딩
- 오름캠프플러터
- 모두연구소
- 생존코딩
- #패스트캠퍼스 #내일배움카드 #국비지원 #K디지털기초역량훈련 #바이트디그리 #자바인강
- 플러터
- 오존석의 생존코딩
- 모두의 연구소 # 오준석의생존코딩# 오름캠프
- 오준석의 생존코딩
- 오름캠프
- 모두의연구소
- 모두의연구소 오준석생존코딩 오름캠프
- Today
- Total
꾸준히 하고싶은 개발자
빅데이터 수집 플럼10월 13일 본문

| 수집->적재-> 처리/탐색 ->분석/응용 =>분석및 응용에서 잘못된부분있으면 처리/탐색으로 가서 다시 작업한다. |
빅 데이터 수집 시스템 구축은 수집에서부터 시작하며 빅 데이터 프로젝트에서 여러 공정 단계가 있는데 그중 수집이 전체 공정 과정에 절반이상을 차지한다. 빅데이터 수집은 내부 전체 시스템에서 부터 외부 시스템(SNS,포털,정부기관)에 이르기까지 매우 광범위하고 다양하다.
프로젝트 초기에는 수집 대상 시스템을 선정하고 그에 따른 연동 규약을 협의 및 분석하는 데 엄청난 리소스가 투입되며 또한 수집 실행 단계에서 업무 요건과 환경의 변화로 이전 단계인 수집 계획 수립으로 다시 돌아가는 경우가 빈번하게 발생되며 그로 인해 그계획과 실행단계가 여러차례 반복되서 수집 인터페이스가 빈번히 수정되는 어려움이 있다.
빅데이터 수집에 활용가 기술
플럼Flume 은 빅데이터를 수집할때 다양한 수집 요구사항들을 해결하기위한 기능으로 구성된 소프트웨어다.
플럼을 수집할때에는 통신프로토콜,메시지 포맷,발생주기,데이터크기등으로 많은 고민을 하게 되는데 플럼은 이러한 고민을 쉽게 해결할 수있는 기능과 아키텍처를 제공한다.
-플럼은 2011년 클라우데라에서 처음으로 소개되었으며 이후 아파치 프로젝트에 기증되어 현재는 아파치 최상위 프로젝트서 전 세계 수많은 엔지니어들이 사용되고있다.
0.9버전 Flume-OG로 불렸고 1.X ->Flume-NG으로 이름이변경되면서 아키텍처가 크게변함

플럼 매커니즘은 소스Source->채널channel-> 싱크Sink 만을 활용하는 매우 단순하면서 직관적인 구조를 갖는다.
플럼의 Source에서 데이터를 로드하고 Channel에서 데이터를 임시 저장해 놓았다가 Sink를 통해 목적지에 데이터를 최종적재한다.
이러한 플럼은 수집 요건에 따라 다양한 분산 아키텍처 구조로 확대 할 수있으며, 아래의 대표적인 4가지 구성방아늘 소개한다.

플럼 아키텍처 유형1 수집과 적재를 할때 주로사용된다.

데이터를 수집 할때 Interceptor를 추가해 데이터를 가공하고 데이터의 특성에 따라 channel에서 다수의 Sink 컴포넌트로 라우팅이 필요할때 구성되며 한개의 플럼 에이젠트안에서 두개이상의 Source->Channel->Sink 컴포넌트 구성 및 관리 가능하다.

플럼 에이전트에서 수집한 데이터를 플럼 에이전트2에이전트3에 전송 할때 로드밸런싱 복제 페일 어버 등의 기능을 선택적으로 수행할수있다. 수집해야할 원천 시스템은 한곳 이지 만 높은 성능과 안정성이 필요로 할때 주로 사용되는 아키텍처다.

데이터가 수집해야 할 원천 시스템이 다양하고 대규모의 데이터가 유일 될때 사용하는 플럼의 분산 아키텍처다.
플럼 아키텍처 1,2,3,4 에서 수집한 데이터를 에이전트5에서 집계하고 이때 플럼 에이전트6으로 이중화해서 성능과 안정성을 보장하는 아키텍처다.
플럼 은 데이터에서 발생하는 로그를 직접 수집하는 역할을 담당한다.
실습
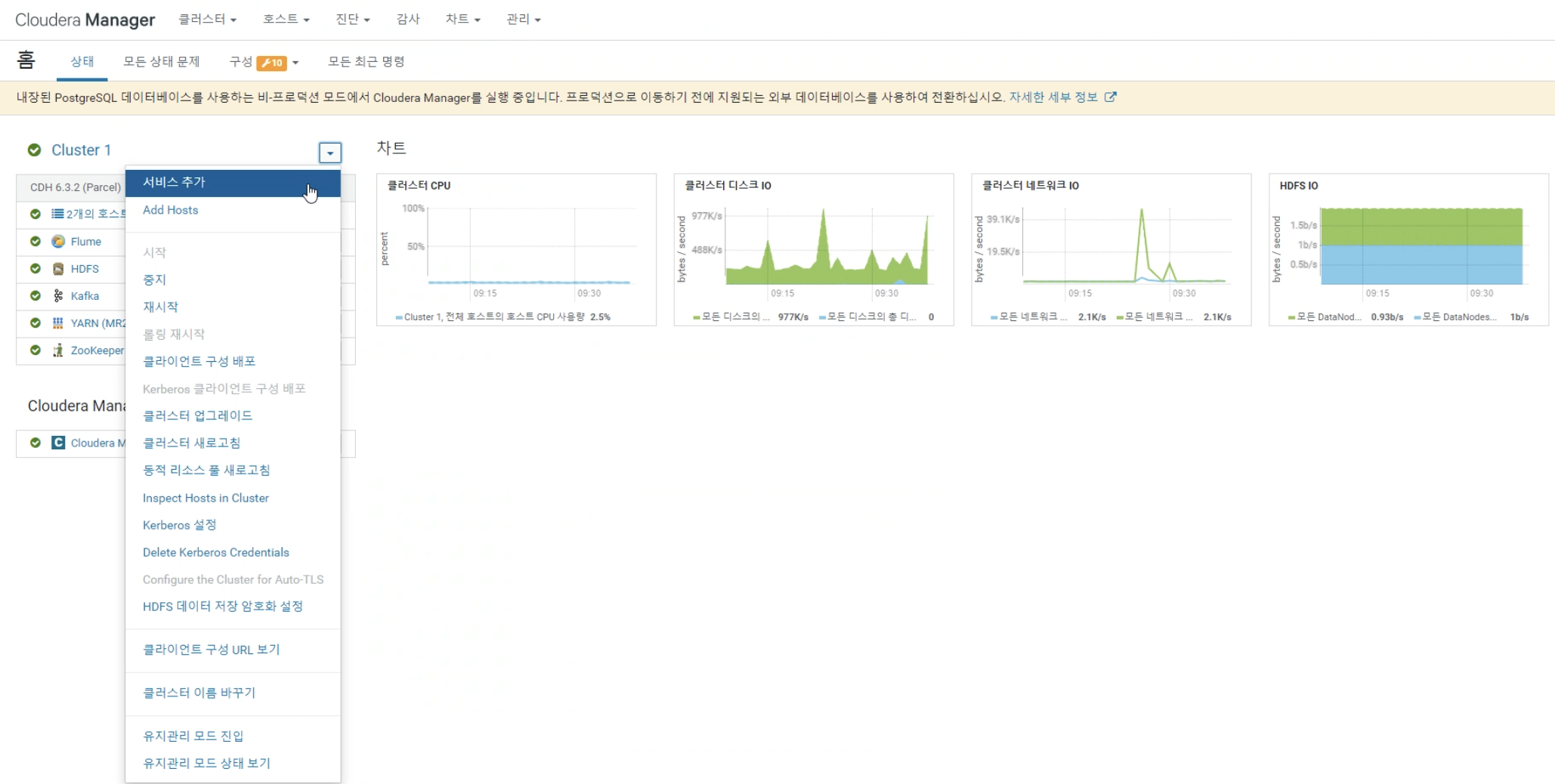


서버호스트를 선택하고 확인하면 완료된다.



서버 호스트 를 server02.hadoop.com을 선택하고 확인 -> 계속하면 완료된다.

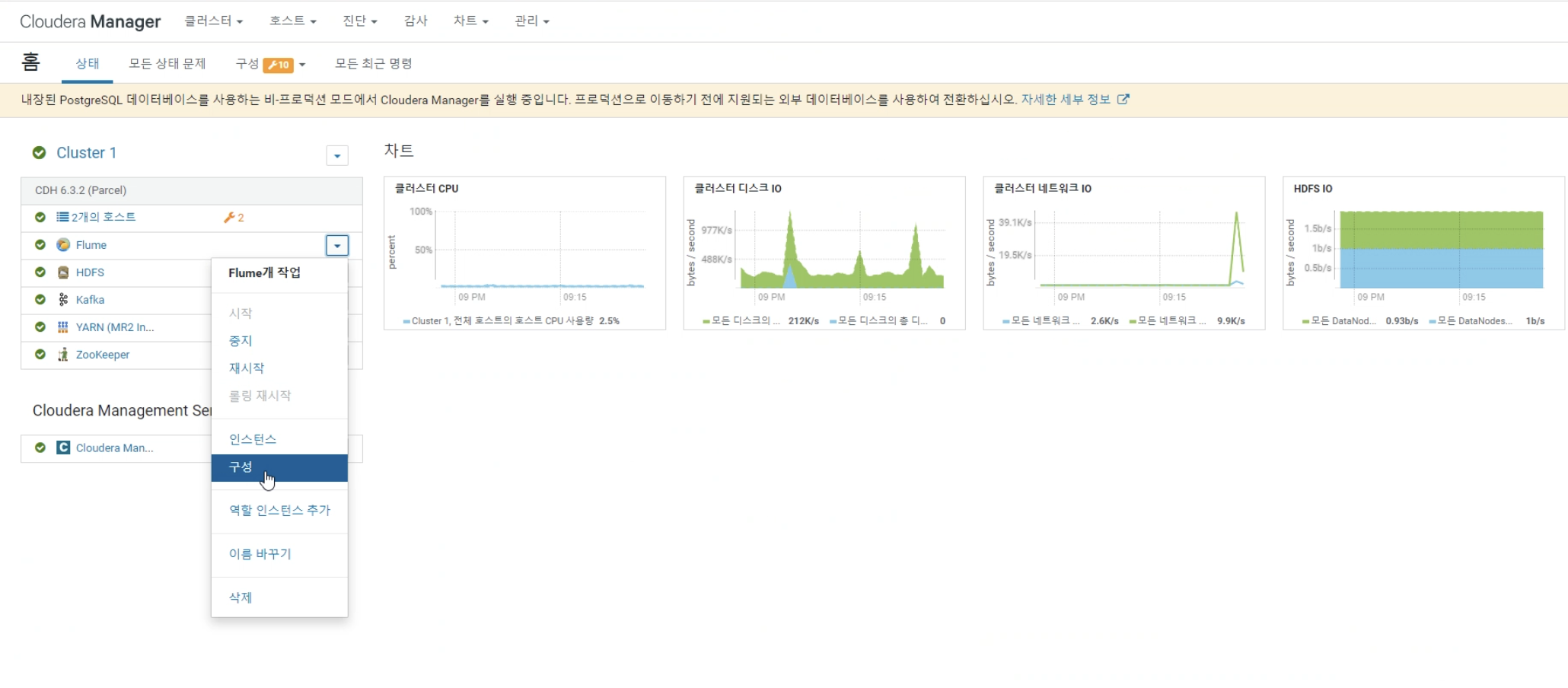



차 infomation 상태 정보 삭제해야 순순한 데이터를 얻기 위해서
'빅데이터 플랫폼' 카테고리의 다른 글
| 빅데이터 처리/탐색(하이브) (0) | 2022.10.24 |
|---|---|
| 빅데이터 적재 2 -실시간 로그 /분석 적재(Hbase,redis) 실습2 자바 스프링 사용해서 웹으로 보기 (0) | 2022.10.22 |
| 빅데이터 수집 Kafka (0) | 2022.10.21 |
| 빅데이터 적재 2 -실시간 로그 /분석 적재(Hbase,redis) (0) | 2022.10.20 |
| 빅데이터 적재 적재1 (대용량 로그파일 적재) (1) | 2022.10.18 |



