
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 오름캠프플러터
- 오준석의 생존코딩
- 생존코딩
- 모두의연구소
- 오존석의 생존코딩
- #패스트캠퍼스 #내일배움카드 #국비지원 #K디지털기초역량훈련 #바이트디그리 #자바인강
- 모두의 연구소 # 오준석의생존코딩# 오름캠프
- 오름캠프
- 모두연구소
- 플러터
- Tag #패스트캠퍼스 #내일배움카드 #국비지원 #K디지털기초역량훈련 #바이트디그리 #자바인강
- ㅇ
- 패스트 캠퍼스
- 모두의연구소 오준석생존코딩 오름캠프
- 오준석의생존코딩
- Today
- Total
꾸준히 하고싶은 개발자
빅데이터 처리/탐색 스파크 본문
스파크
-하이브는 복잡한 맵리듀스를 하이브 QL 로 래핑해 접근성을 높일 수있었지만 맵리듀스 코어를 그대로 사용함으로써 성능면에서는 만족 스럽지 못했다.
-반복적인 대화형 연산작업에서는 하이브가 적합 하지 않는다.
-하이브 단점을 극복하기위해서 다양한 시도을 했는데 그중하나가 스파크다
-스파크는 UC 버클리 의 AMPLab에서 2009년 개발 되었는데 2010년 오픈 소스로 공개 됐고, 2013년 아파치로 재단으로 이전되면서 최상위 프로젝트가 됐다.
빅데이터 분야에서는 핫한 기술중 하나로 2016년 3월 안정 버전인 1.6.1릴리스 됐고 최근에는 3.X버전이 나왔다.
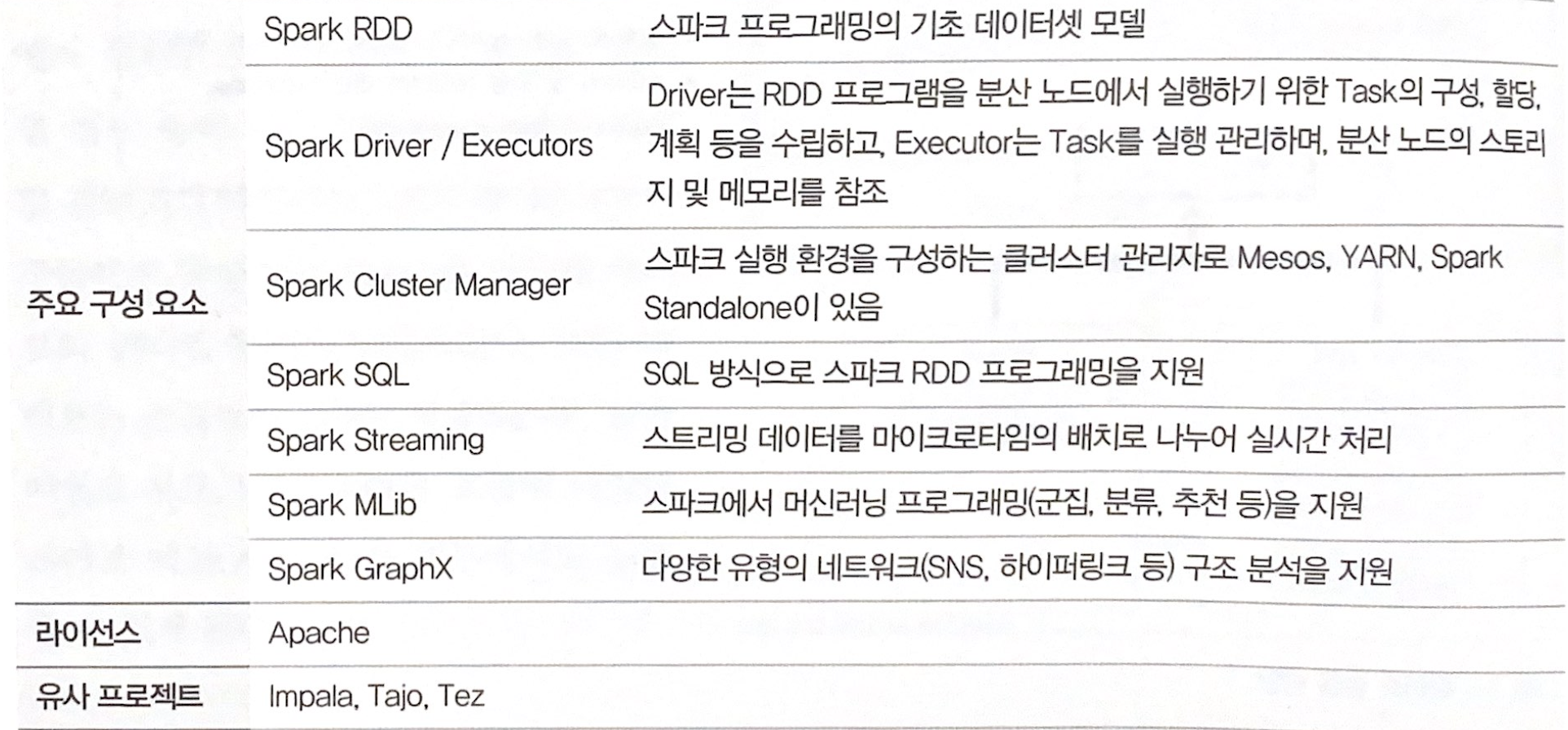
스파크 아키텍처
-스파크의 가장 큰 특징은 고성능 인메모리 분석이다.
-기존 맵리듀스 기반의 하이브 또는 피그의 경우 하둡의 로컬 디스크에 의존해 대량의 데이터를 로드하고 생성함으로써 높은 IO 발생과 그로인한 레이턴시를 피할 수없다.
-스파크는 데이터 가공 처리를 인메모리에서 빠르게 처리한다
-여기에 스파크 SQL 스파크 스트리밍 스파크 머신러닝 등의 기능을 제공 하고 있어 활용성이 높고 다양한 클라이언트 언어 ( 자바, 파이썬, 스칼라)등 라이브러리를지원해 범용성도 뛰어나다 또는 스파크코어의 기능(스케줄링, 지원관리,장애복구,RDD 관리등 )에 API 로 접근할 수있어 유연한 아키텍처 구성이 가능하다.
-스파크 엔진은 대규모 분산 노드 에서 최적의 성능을 낼 수있는데 스파크의 분산 노드로 아파치 메소스(Apachr Meos), 하듑 얀을 이용한다.
데이터소스영역은 높은 호환성을 보장함으로써 HDFS Hbase 카산드라(Cassndra),일래스틱 서치(Elastic Search)등을 연결해 이용 할 수있다.

설치



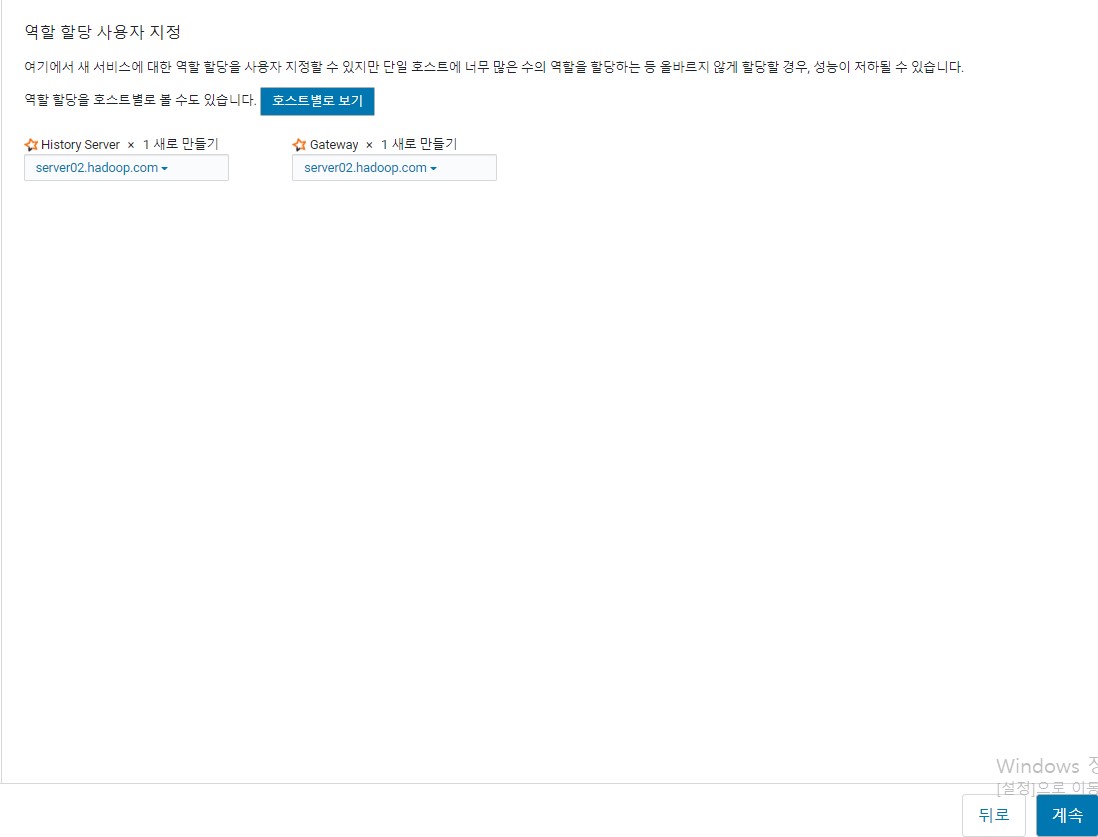



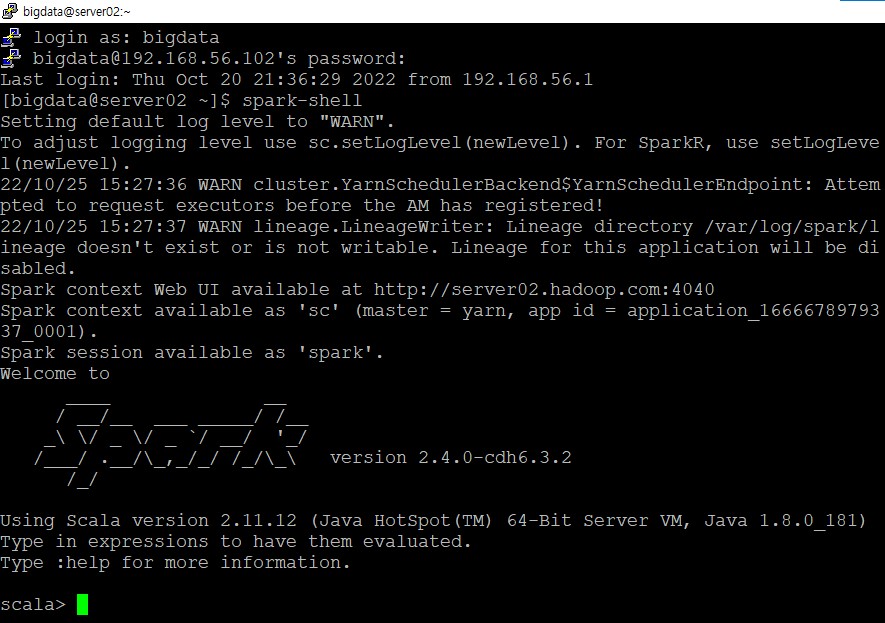
실습


'빅데이터 플랫폼' 카테고리의 다른 글
| 빅데이터 처리/탐색(휴) (0) | 2022.10.27 |
|---|---|
| 빅데이터 처리/탐색 우지 (0) | 2022.10.26 |
| 빅데이터 처리/탐색(하이브) (0) | 2022.10.24 |
| 빅데이터 적재 2 -실시간 로그 /분석 적재(Hbase,redis) 실습2 자바 스프링 사용해서 웹으로 보기 (0) | 2022.10.22 |
| 빅데이터 수집 Kafka (0) | 2022.10.21 |



