
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 모두의연구소 오준석생존코딩 오름캠프
- 모두의연구소
- 오존석의 생존코딩
- 오준석의생존코딩
- #패스트캠퍼스 #내일배움카드 #국비지원 #K디지털기초역량훈련 #바이트디그리 #자바인강
- 생존코딩
- 모두연구소
- 모두의 연구소 # 오준석의생존코딩# 오름캠프
- 오름캠프플러터
- 패스트 캠퍼스
- 오름캠프
- ㅇ
- Tag #패스트캠퍼스 #내일배움카드 #국비지원 #K디지털기초역량훈련 #바이트디그리 #자바인강
- 오준석의 생존코딩
- 플러터
- Today
- Total
꾸준히 하고싶은 개발자
K-평균 군집화 분석+ 그래프 본문
비지도 학습 :unsupervised learning은 훈련 데이터에 타깃값이 주어지지않은 상태에서 학습을 수행하는 방식이다.
훈련 데이터를 학습하여 모델을 생성하면서 유사한 특성(관계,패턴)을 가지는 데이터를 클러스터로 구성하며 그리고 새로운 데이터의특성을 분석하여 해당하는 클러스터를 예측한다.
군집화:clustering sms 테이터를 클러스터cluster 즉 군집으로 구성된다.
군집화 는 군집에 대한 정보를 가지고있지 않기 때문에 비지도 학습을 수행하여 데이터간 관계를 분석하며 유사한데이터를 군집으로 구성한다. 군집화를 위한 대표적인 알고리즘에는 K-평균과 계층적 군집이있다.
K-평균알고리즘
K-평균 알고리즘은 K개의 클러스터를 구성하기 위한것이다.
-K개의 중심점을 임의의 위치를 잡고 중심점을 기준으로 가까이 있는 데이터를 학인한뒤 그들과 거리(유클리디안 거리의 제곱을 사용하여계산)의 평균지점으로 중심점을 이동하는방식이다.
-이동한 위치에서 가까이 있는 데이터를 다시 확인하고 그들의 평균 지점으로 중심점을 이동하는 과정을 반복한다.
-더 이상 이동이 발생 하지않는 위치를 찾으면 각 중심점을 기준으
로 K개 의클러스터 가 구성된다.
-가장많이 활용하는 군집화 알고리즘이지만 클러스터 의 수를 나타내는 K를 직접 지정해야 하는 문제가 있어서 가장 좋은 K개 클러스터를 찾는데 엘보방식과 실루엣방식이 있다.
엘보방식
클러스터의 중심점과 클러스터 내의 데이터 거리가 차이의 제곱값합은 왜곡(distortion)이라고하며 엘보방식은 왜곡방식을 이용해서 클러스터를 찾는데 최적이다.
클러스터의 개수k의 변화에따른 왜곡의 변화를 그래프로 그려보면 그래프가 꺾이는 지점인 엘보가 나타나는데 그지점의 K를 최적K로 선택한다.
실루엣 방식(Silhouette analysis)
실루엣 방식은 클러스터 내에 있는 데이터가 얼마나 조밀하게 모여있는지 를 측정하는 그래프도구다. 데이터 I가 해당 클러스터 내의 데이터와 얼마나 가까운지를 나타내는 클러스터 응집력 a(i)와 가장 가까운 다른 클러스터 내의 데이터와 얼마나 떨어져있는가를 나타내는 클러스터분리도 cluster separation b(i)를 이용하여 데이터엣계수s(i)를 계산한다. 실루엣 계수는 -1~1사이의 값을 가지며 1에가까울수록
좋은군집화를 의미한다.


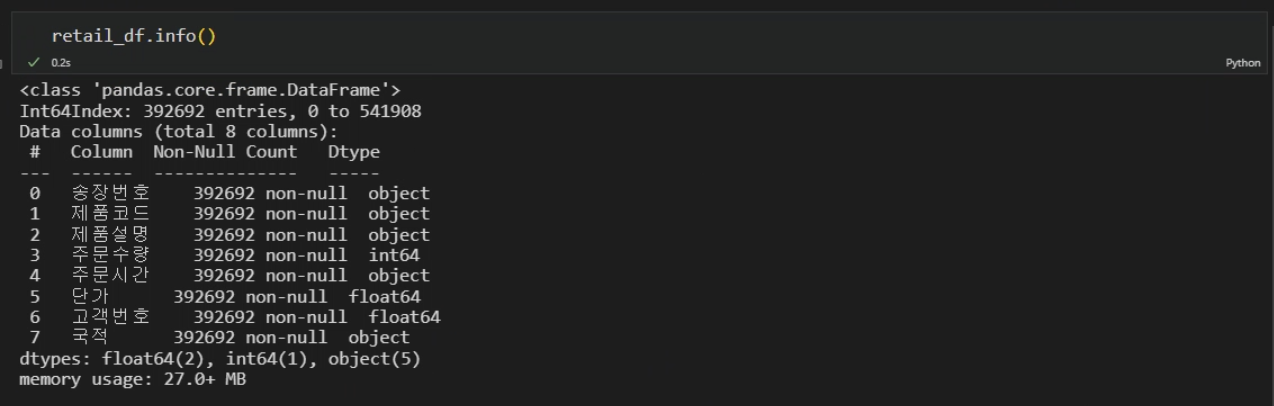
실습






'python > BigdataAnalysis' 카테고리의 다른 글
| 토픽 분석+ LDA토픽 모델 (0) | 2022.10.01 |
|---|---|
| 토픽 모델링 (1) | 2022.09.29 |
| 로지스틱 회귀 분석 (0) | 2022.09.27 |
| 텍스트 빈도 분석(영어) (0) | 2022.09.27 |
| 상관 분석+히트맵 (0) | 2022.09.21 |



