
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 플러터
- #패스트캠퍼스 #내일배움카드 #국비지원 #K디지털기초역량훈련 #바이트디그리 #자바인강
- 오준석의 생존코딩
- 오름캠프플러터
- 오준석의생존코딩
- 모두의연구소 오준석생존코딩 오름캠프
- 오름캠프
- 패스트 캠퍼스
- 모두의 연구소 # 오준석의생존코딩# 오름캠프
- Tag #패스트캠퍼스 #내일배움카드 #국비지원 #K디지털기초역량훈련 #바이트디그리 #자바인강
- 오존석의 생존코딩
- ㅇ
- 모두연구소
- 모두의연구소
- 생존코딩
- Today
- Total
꾸준히 하고싶은 개발자
토픽 모델링 본문
텍스트 마이닝
텍스트 마이닝 text mining은 비정형의 텍스트 데이터로부터 패턴을 찾아내어 의미 있는 정보를 추출하는 분석 과정 또는 기법을 말한다.
-텍스트마이닝은 데이터 마이닝과 자연어처리 natural language process, 정보검색 등의 분야가 결합된 분석 기법을 사용하여 텍스트 데이터로부터 유용한 고급 정보를 찾는 과정이다.
| 텍스트 전처리-->특성 백터화--> 머신러닝 모델 구축 및 학습/평가 프로세스 수행 |
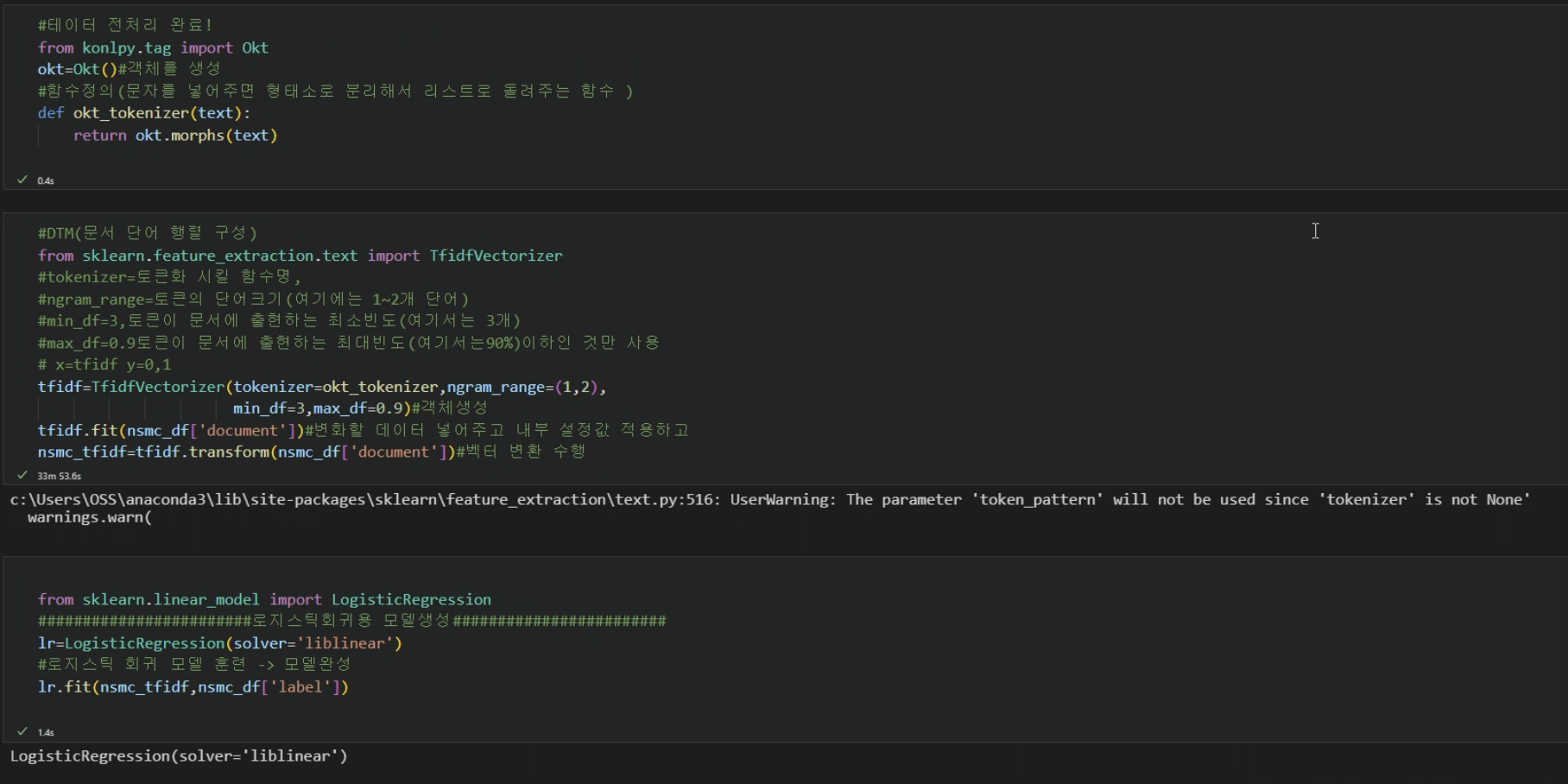
텍스트 전처리는 토큰화,불용어제거, 표제어추출,형태소분석 등의 작업이 포함된다.
특성 벡터화와 특성 추출
-머신러닝 알고리즘으로 분석하기 위해서는 텍스트를 구성하는 단어 기반의 특성 추출(feature extraction)을 하고 이를 숫자형 값인 벡터 값으로 표현해야한다.
- 특성 벡터화(feature vectorization)의 대표적인 방법으로는 BoW Bag of Words 와 Word2Vec 이 있다 여기에서 BOW는 문서가 가지고 있는 모든 단어에 대해 순서는 무시한채 빈도만 고려하여 단어가 얼마나 자주 등장하는 지로 특성 벡터를 만드는 방법이다. Bow 에는 카운트 기반 벡터화 와 TF-IDF기반 벡터방식이다.
카운터 기반 벡터화
단어의 피처에 숫자형 값을 할당할때 각문서에서 해당 단어가 등장하는 횟수, 즉 단어 빈도(tern frequency)를 부여하는 벡터화 방식이다. 전체 문서에 등장한 단어를 기반으로 어휘 사전을 생성하고 단어마다 등장 횟수를 카운터 하여 해당 단어의 정수 벡터 값 으로 할당한다. 문서별 단어의 빈도를 정리하여 문서 단어 행렬(DTM)document term Matrix을 구성하는 데 단어 출현 빈도가 높을 수록 중요한 단어로 다루어진다. 문서d에 등장하는 단어T의 횟수는 t 는 tf(t,d)로표현한다.
머신러닝 분야에서는 특성보다 피처(featrue)라는 용어를 많이쓰인다.
카운트 기반 벡터화는 사이컷런의(CountVectorizer 모듈에서 제공한다.
TF-IDF 기반 벡터화
카운터기반 벡터화에서 카운터 값이 높은 단어는 문서에서 많이 사용된 중요한 단어 일수도 있지만 단지 문장 구성상 많이 사용하는 단어 일 수도 있다. 이런 문제를 보완하기위해 TF-IDF기반 벡터화 를 사용한다. TF-IDF 벡터화는 특정 문서에 많이 나타나는 단어는 해당 문서에 단어 가중치를 높이며 범용적으로 사용하는 단어로 취급하여 가중치를 낮추는 방식이다. 문서 D 단어 T의 TF-IDF는
| 문서 D 단어 T의 TF-IDF는 tf-idf(t,d)=tf(t,d)*idf(t,d) |
여기서 idf(t,d)는 역문서 빈도는 inverse document frequency) |
감성분석
감성분석은 텍스트에서 사용자의 주관적인 의견이나 감성 태도를 분석하는 텍스트 마이닝의 핵심 분석 기법 중 하나로 오피니언 마이닝이라고 한다. 감성 분석은 텍스트에서 감성을 나타내는 단어를 기반으로 긍정또는 부정의 감성을 결정한다. 감성 사전 기반의 감성분석은 감성 단어에 대한 사전을 가진 상태에서 단어를 검색하여 점수를 계산한다. 최근 머신러닝 기반의 감성분석이 늘어나고 있는데 감성 분류 클래스가 있는 데이터를 지도학습으로 훈련하여 감성분류 모델을 구축한뒤 분석할 데이터를 감성 분류 모델에 적용하여 분석한다.
토픽 모델링
토픽 모델링은 문서를 구성하는 키워드를 기반으로 토픽을 추출하고 추출한 토픽을 기준으로 문서를 분류 및 분석하는 기법이다 . 문서에서 다루는 토픽을 도출하여 동향을 파악하고 새로운 문서의 토픽을 예측하는 분석에 사용된다.
LDA
LDA 는 대표적인 머신러닝 기반 토픽 모델링 기법이다. 디리클레 분포를 이용하여 주어진 문서에 잠재된 토픽을 추론 하는 확률 모델 알고리즘 을 사용한다. 하나의 문서에 여러개의 토픽을 구성하고 문서의 토픽 분포에 따라서 단어를 분포가 결정된다고 가정한다.
LDA기반의 토픽 모델링에서 토픽의 개수 K는 토픽 분석의 성능을 결정 짓는 중요한 요소이며 사용자가 지정해야 할 하이퍼 매개변수다.
py LDAvis
LDA를 이용한 토픽 모델링 분석 결과를 시각화 하는 라이브러리다.
실습 네이버 영화리뷰 평점 감성분석






'python > BigdataAnalysis' 카테고리의 다른 글
| 딥머닝 실습 (신경망) (0) | 2022.10.06 |
|---|---|
| 토픽 분석+ LDA토픽 모델 (0) | 2022.10.01 |
| K-평균 군집화 분석+ 그래프 (0) | 2022.09.28 |
| 로지스틱 회귀 분석 (0) | 2022.09.27 |
| 텍스트 빈도 분석(영어) (0) | 2022.09.27 |



