
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 모두의연구소 오준석생존코딩 오름캠프
- Tag #패스트캠퍼스 #내일배움카드 #국비지원 #K디지털기초역량훈련 #바이트디그리 #자바인강
- ㅇ
- 모두연구소
- 패스트 캠퍼스
- 생존코딩
- 오준석의생존코딩
- 플러터
- 모두의 연구소 # 오준석의생존코딩# 오름캠프
- #패스트캠퍼스 #내일배움카드 #국비지원 #K디지털기초역량훈련 #바이트디그리 #자바인강
- 오준석의 생존코딩
- 오름캠프
- 오름캠프플러터
- 오존석의 생존코딩
- 모두의연구소
- Today
- Total
꾸준히 하고싶은 개발자
빅데이터 분석 (임팔라) 본문
빅데이터 탐색 단계가 데이터를 관찰하고 이해해하며 전처리하는 과정이라면 빅데이터분석은 탐색과 분석을 반복하며 의미 있는 데이터를 추출해 문제를 찾고 인사이트를 얻어 의사결정을 내리는 단계다.
-필요시 의사결정을 돕기위한 요약정보를 만들어 제공한다. 사실 탐색과 분석의 경계는 매우 모호 하지만 목적에 따라 분석의 유형5 가지로정의한다.
1.기술분석:분석초기 데이터의 특징을 파악하기 위해 선택 ,집계, 요약 등 양적 기술분석을 수행한다.
2.탐색분석:업무 도메인 지식을 기반으로 대규모 데이터셋의 상관관계나 연관성을 파악한다.
3.추론분석: 전통적인 통계분석 기법으로 문제에 대한 가설을 세우고 샘플링을 통해 가설을 검증한다
4.인과분석:문제해결을 위한 원인과 결과 변수를 도출하고 변수의 영향도를 분석한다
5.예측 분석: 대규모 과거 데이터를 학습해 예측모형을 만들고 , 최근의 데이터로 미래를 예측한다.
다양한 분석 기술을 통해 빅데이터의 가치는 Raw데이터(순수데이터) ->정보->통찰력->가치 순으로 변하게 된다
-가운데 통찰력을 갖게 되는 단계에서 빅데이터의 활용 효익이 만들어지기 사작하는데 주로 상품및 서비스 개발 마케팅 및 켐페인 지원 리스크 관리등 영역에서 주요 의사결정을 내릴때 빅데이터 이용한다.
빅데이터 분석은 기존 전통적인 분석과 어떤차이가 있을까?
-두가지 큰 차이점이 있는데 2V(Volume,Variety)와 관련성이 있다.
-먼저 빅데이터 분석의 최대 장점은 저비용 고효율이다.
-빅데이터분석은 대규모 데이터를 분석할때 오픈 소스의 강력한 분산기술과 낮은 하드웨어 소프트웨어 비용으로 수평적으로 선평 확장이 가능하다.
-RDBMS 기반의 분석은 수직적 성능 향상과 고비용의 제한적인 확장성만 지원해 대규모 데이터를 분석할때 한계가 발생한다.
-빅데이터는 내부(정형) 데이터와 외부(비정형):SNS 포털 날씨 위치 뉴스등)데이터를 결합해 분서 시 다양한 (Variety)관점을 제공 할수 있다.
-외부 빅데이터를 보유한 조직은 기존의 내부데이터와 결합해 분석시야가 넓어지고 당면한 비즈니스 문제를 해결하기 위한 인과 및 상관관계 같은 정보의 발견이 내부 데이터만으로 분석할때보다 커져 차별화 된 인사이트 도출이 가능해진다.
-머신러닝(딥러닝)모델의 변수로 외부 데이터를 적극 활용해 예측 모델의 정확도를 높여 미래를 내다 볼수있는 분석력도 강화된다.
임팔라
2008년 하이브 맵리듀스를 대체하는 SQL on Hadoop의 도구로 자리 잡았다.
생태계에서는 하이브의 배치성분석에 만족하지 못하고 빅데이터 분석을 인 메모리 기반의 실시간 온라인 분석으로 까지 확대하길 원했다.
-구글이 가장 먼저 이애대한 변화하기 시작했다.
-기술이 적용된 드레멜 논문을 2010년 발표했으며 이 논문의영향을 받는 클라우데라는 곧바로 임팔라 개발에 착수하고 2012년 10월 실시간데이터분석 질의 가능한 임팔라를 오픈 소스로 발표했다.
임팔라 아키텍처
-임팔ㄹ의 아키텍처는 하둡의 분산 노드에서 대규모 실시간 분석을 위해 Impalad Statestored,Catalogd 라는 컴포넌트가 설치된다.
-Impalad는 HDFS의 분산 노드 상에서 실행계획과 질의 작업을 수행하는 데몬이다.
-Statestored는 Impalad의 기본 메타정보부터 각 분산 노드에 설치돼 있는 Impalad를 관리하는역할을 한다.
-Catalogd는 Impalad와 Statestored와 통신하면서 임팔라SQL의 실행과 변경 이력을 관리한다.
임팔라 활용방안
하이브를 쿼릴르 임팔라 쿼리로 바꾸고 데이터셋을 실시간으로 탐색한다. 하이브쿼리는 대부분 임팔라 쿼리와 호환 가능하며 , 하이브 대비 빠른 응답속도를 보장한다.
설치



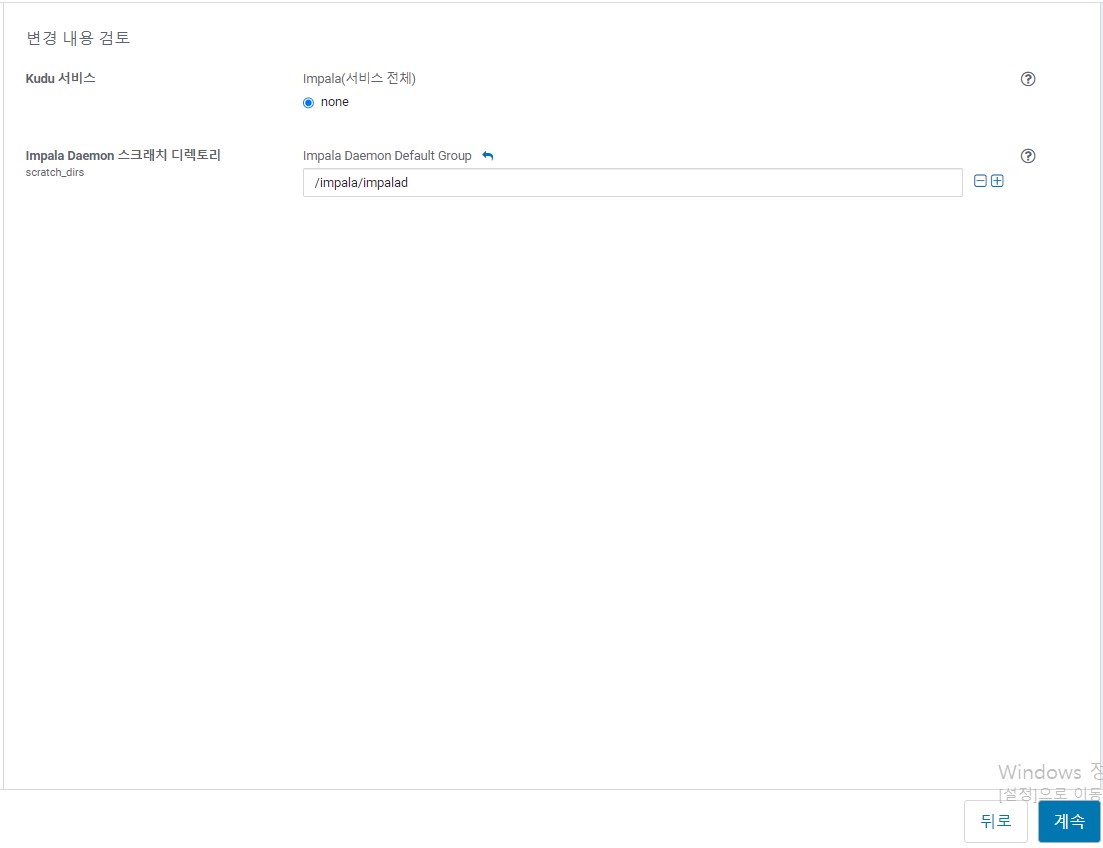



hive Hbase Oozie 등 사용하기 None 해제 해줍시다.
실습하기











'빅데이터 플랫폼' 카테고리의 다른 글
| 빅데이터 분석 머하웃(Mahout) (0) | 2022.11.02 |
|---|---|
| 빅데이터 분석(제플린Zeppelin) (1) | 2022.11.01 |
| 빅데이터 처리/탐색(휴) (0) | 2022.10.27 |
| 빅데이터 처리/탐색 우지 (0) | 2022.10.26 |
| 빅데이터 처리/탐색 스파크 (0) | 2022.10.25 |



